
Are juror decisions full of “NOISE,” and what can we do about it?
In his recent book co-authored with Olivier Sibony, and Cass R. Sunstein, Daniel Kahneman, a famous psychologist, and economist, Emeritus Professor at Princeton University, and Nobel Prize-winning author of the highly influential Thinking, Fast and Slow, describes how Noise – the title of his new book – is a hidden yet prevalent issue in human judgment.
What is noise and how is it different from bias? To what extent can “noise” cripple data modeling effectiveness? And, more pragmatically, how can it be contained or avoided in the context of legal practice?
Although giving a full account of the book is certainly an unrealistic endeavor, here are a few of our takeaways:
Bias and cognitive bias
In Thinking, Fast and Slow, Daniel Kahneman had largely described “bias”. Biases can be influenced by judgment, experience, social norms, assumptions, and more. Cognitive biases are severe and systematic errors in thinking when trying to process and interpret data for decision-making; biases that are based on concepts that may or may not be accurate. Hence, a critical flaw in human decision making.
All bias refers to issues that arise from our tendency to choose systems of reasoning that have the virtue of being fast, but often the vice of being inaccurate and to subject us, humans, to make errors. This is a heuristic to decision-making.
Heuristics are mental shortcuts to help people solve problems, formulate an opinion, aid in making decisions and judgments more quickly and efficiently. Heuristics can be helpful, but they can also lead to cognitive biases.
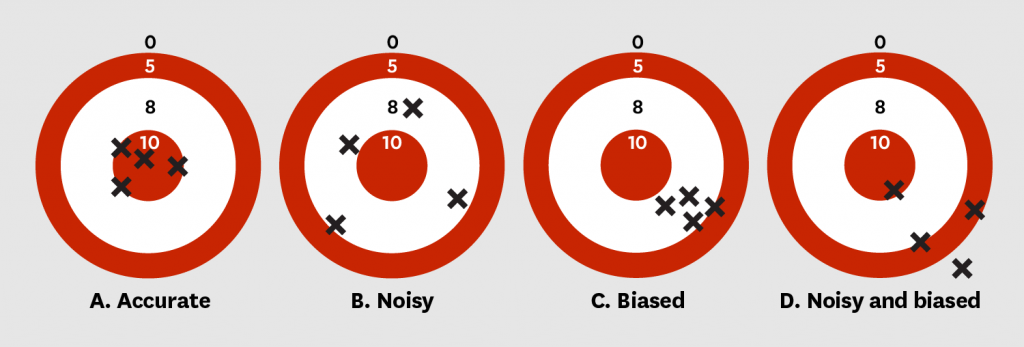
Differentiating bias and noise
The key term in differentiating bias and noise is that bias is systematic, which implies an identifiable cause. For example, in the case of hospital malpractice, a juror’s judgment may be biased because the juror knows the plaintiff or because they have worked for the hospital.
As Kahneman points, the good news is that, more often than not, biases – or at least, the most obvious ones, like in the previous example – are easily caught. In the context of juror selection, it is extremely important to select participants that are free of juror bias. When attorneys on both sides begin to evaluate the jurors, these jurors will be asked if they know the plaintiff or the defendant in any capacity. Assuming each response from each juror is truthful, jurors that are suspected to hold judgment biases would be removed from the pool, thereby removing the bias itself.
Now, we easily see what biases are, but then, what about noise? As with many concepts derived from statistics, the concept of noise is known under a lot of terms. While Kahneman et al. use “noise” in reference to signal detection, Psychologists, and more specifically, Psychometricians, refer to this concept as (low) reliability, (low) consistency, or (high) standard error of measurement. Daniel Kahneman explains that noise is different from bias because it is not systematic and thus less easily attributable to a cause. Instead, noise is random – or at least, caused by so many unknown factors that it appears to be random.
Noise happens when a person’s decision one day could have been different another day. Noise happens when a person’s judgment is different from another person’s, even though they seem to share similar characteristics. Noise happens when fluctuating phenomena, like emotional states, moods, stress, discussions with others, misunderstandings, make our judgments inconsistent and unreliable. The “noise” is that flaw in human judgment making it harder to detect than cognitive bias.
Bias is a problem, but guess what? So is noise!
Take for example the psychological study done by Shai Danziger, Jonathan Levav, and Liora Avnaim-Pesso in 2011, entitled Extraneous factors in judicial decisions. The aim was to test the common caricature that justice is dependent on “what the judge ate for breakfast”.
They found that judges gave more favorable decisions directly after a food break. More importantly, they found that favorable rulings were approximately 65% directly after eating and that the number dropped to nearly 0% by the end of the session. After the end of the session, and another food break, favorable rulings shoot back up to around 65%.
Therefore, contrary to bias, causes for noise are so plentiful that identifying all of them becomes a pointless strategy. You cannot control a juror’s state perfectly, and, even if you could, you would not be sure how it would impact their decisions and actions.

Noise in the context of court
What are the consequences of noise in the context of court and jury trials? Why bother with noise? Imagine one unbiased juror having important leadership skills and personality traits that are likely to promote them to have substantial influence, formal or not, over the other jurors. That one juror is holding a lot of power over the court’s decisions, such as sentencing or evaluating the compensation of damages. Arguably the perfect juror! Well, that juror could have had a bad day. Had plumbing to fix in their home. An argument with someone. A stock market crash tanking their retirement account. Congestion on the road. Let’s stop there, you get the point: Even that unbiased juror’s actions will rarely if ever, depend only on what happened in the courtroom (i.e., the signal). It will also depend on the rest: The noise.
What can we do about it?
In their book, Kahneman and his co-authors advance several general strategies. They especially argue that decision processes should be more formalized as algorithms (rather than left to noisy human judgments), which would make them more standardized and reproducible, and thus would reduce their noise. Whether it is desirable or not to replace or supplement jurors with some kind of artificial intelligence is perhaps a valid question, but probably more of an ethical or philosophical question. In general, however, this is how many issues are already solved. The last time you had to go from point A or point B when knowing the way, did you ask a person? Chances are you turned to your favorite navigation app instead.
Now, at the present time and for the foreseeable future, jurors are persons. And that probably means that judgments will remain quite noisy for a while – maybe that’s what makes them interesting (entertaining, even?). The good news is, we can leverage the power of data science and artificial intelligence to reduce noise and make clearer sense of human behavior.
Decision hygiene: a rational choice?
First, what is decision hygiene? It is when you combine multiple independent judgments. When different people are trying to make a decision, instead of assigning this to one person, why not get all to make their judgments independently and then take the average or some variation of this. What you need to do though is preserve the independence of each person’s judgment before you aggregate.
Keep in mind that decision hygiene, is like “cleaning” the decision so it is important to remember that competence also matters. In the medical field, some diagnosticians are more experts than others. You need to choose the best people, those that will be most accurate because they are also going to be less biased. But, guess what? They’re also going to be less noisy! This means, there will be less random error in their judgment.
Science and rationality
Science and rationality in decision making? Yes, it is more rational than you would think. This is another approach to noise reduction. That is, to use algorithms or a set of rules, or artificial intelligence, in place of human judgment. “Wherever there is judgment there is noise,” said Olivier Sibony. But wherever it is you want to eliminate noise, you must also take away the human element of judgment. The beauty of algorithms is they do just that. They eliminate the noise. The machine, unaffected by mood, time of day, or what they ate for breakfast, will churn out the same judgments so long as the algorithm doesn’t change. And this provides a level of confidence too.
Data hygiene in action
At Jury Analyst, we build surveys around psychological research and measures – such as personality traits – whose reliability has been previously demonstrated with hard evidence (either in the specialized scientific literature or in our own data). We also use behavioral economics, which is studying the effects of certain factors on decision making. How factors in cognitive psychology such as the effect of psychological, cognitive, cultural, and social factors, and emotions weigh in when a person is deciding and if any of this changes their perception.
By doing this, we are better able to reduce the noise in the measurements we use, and even diagnose noise-related issues. Obviously, there are often some compromises to make here. Namely, in this context, frequently questionnaires that are longer have more chances, statistically speaking, to be more reliable. At the same time, we know that focus group survey respondents and prospective jurors are prone to survey fatigue (which is also a source of noise!), so that means that we have to find robust but short questionnaires – or improve them ourselves – so that we can make reliable predictions.

How else can you reduce noise?
Another significant way for us to reduce noise is to agglomerate information from several sources. A single measure – say, political orientation – is still only one source of information. Like the implications of that one juror. In a potential juror’s decisions, political orientation does not account for everything, obviously. But it could account for a little bit in some cases. That means that our job is to piece together an arsenal of information sources that will be the most relevant in composing the best prediction. Importantly, that also means trying to find several non-redundant sources of information!
For example, if we used political personality traits (like, right-wing vs. left-wing orientation) and reported past political votes, we would have largely overlapping information to base our prediction on. Instead, we would for example gather information from personality traits, values, socio-demographic variables, how the case is perceived, emotional responses, etc. Finally, we integrate this information using sophisticated, and more importantly highly predictive, statistical methods like machine learning algorithms.
Conclusion
To both conclude and to come full circle here, we are also somewhat non-Kahnemanians, in that we do not and would not solely rely on machine learning algorithms to provide you with meaningful, insight and recommendations, predict case outcomes, select jurors, and win more cases. Algorithms are certainly performant companions, as they help us sort through the noise of thousands of survey responses, but we also know that we have to use our expertise and data combing skills to modify and fine-tune our statistical models. This is imperative when it comes to interpreting data in a comprehensive, meaningful, and actionable way. There is always a part of the information and noise that remains complex and narrative (dare we say human?) in a case, and, presently, it is not entirely captured by even the most robust of questionnaires and algorithms. This is why, at Jury Analyst, we strive to personalize and tailor our data collection and analyses in order to address the unique noise associated with each case.